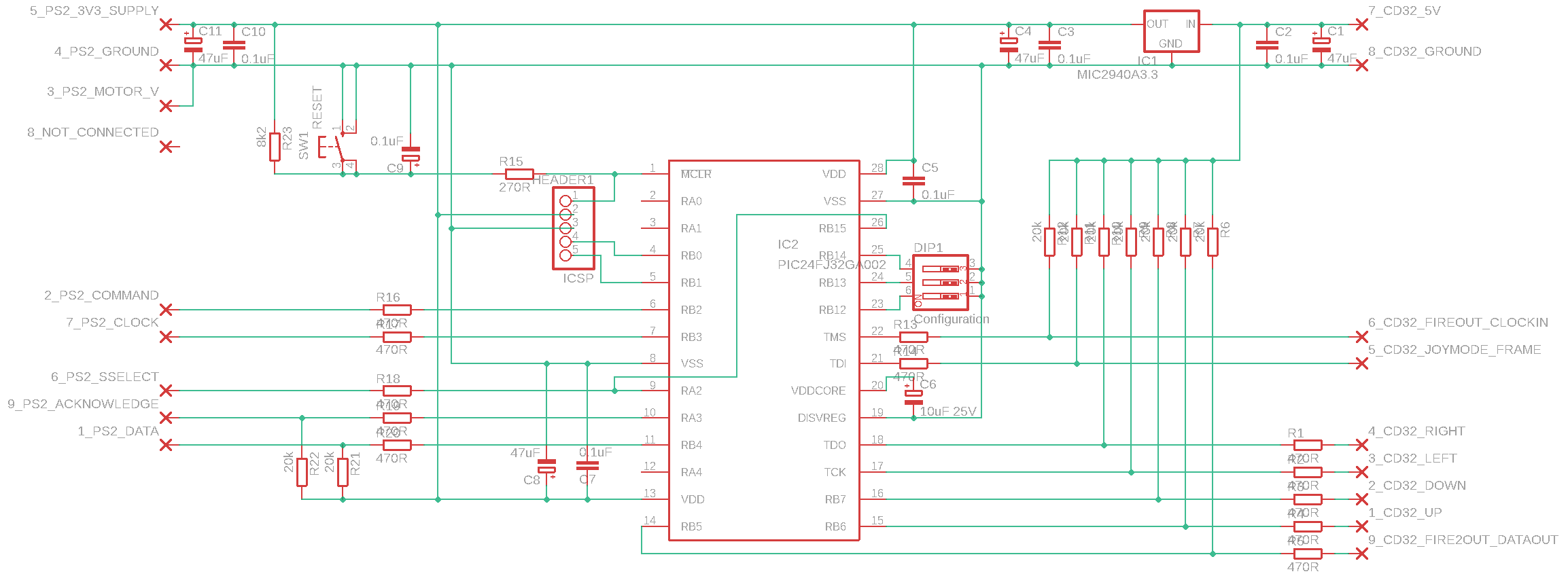
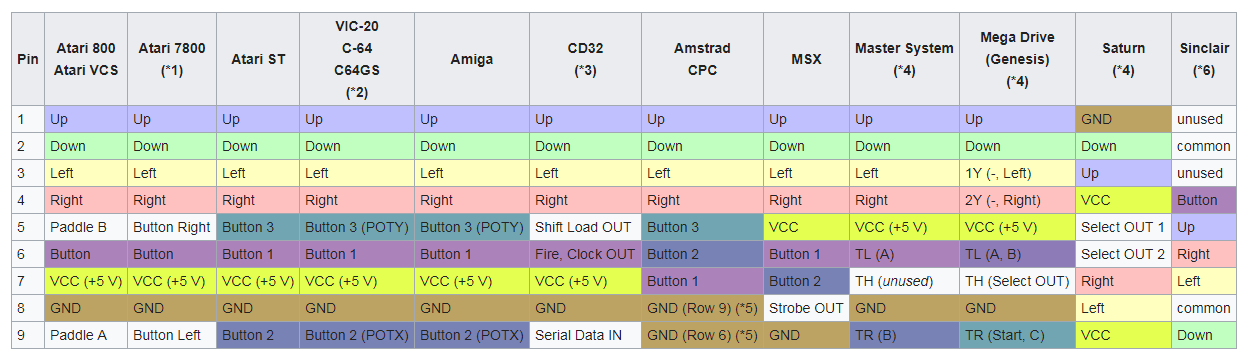
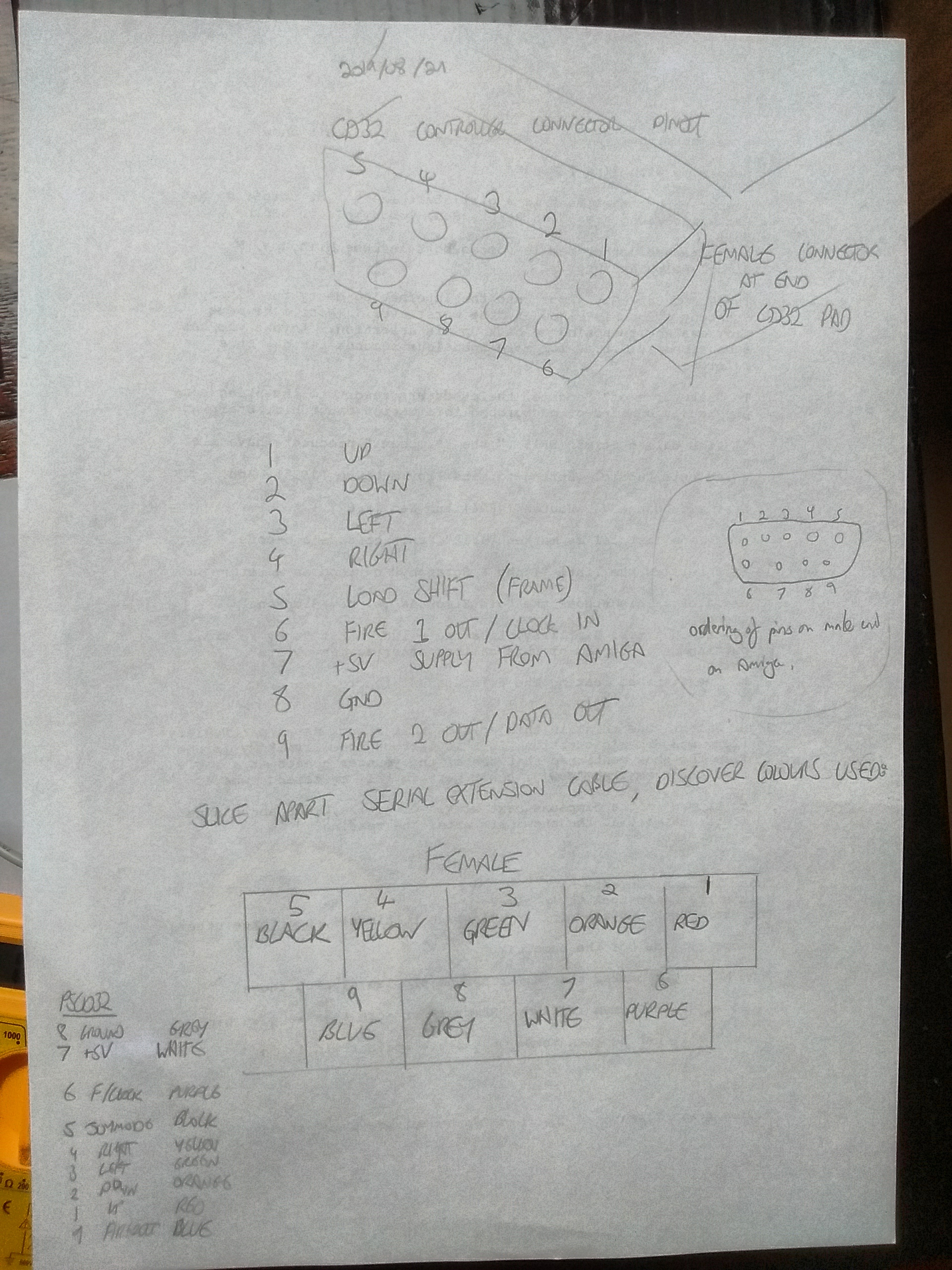
Constructing A Semi-Automatic Abstraction Around It
I'm going to adapt the previous implementation, but change the resolution of the timer I'm using. Instead of triggering on every possible protocol bit transition, I'm going to consider 'byte sending opportunity' units.
In the Curious Inventor photograph, I can see some timing characteristics:
• ATTENTION is pulled low first.
• There's a delay before any transmissions take place.
• CLOCK is pulsed and 0x01 is transmitted LSB first.
• There's a delay before the next byte is sent.
• The next byte is sent, nine bytes in total.
• There's delay after the last byte.
• COMMAND and ATTENTION are released.
• There is potentially a delay before the next communication.
If I consider the time span between two adjanced byte sending events as the 'byte sending opportunity frequency', I can develop a protocol that incorporates all the necessary delays like so:
 The vertical lines indicate timer events.
When a poll request occurs:
• ATTENTION is pulled low. Nothing else happens until the next timer event.
• Bytes are sent on successive timer events until none are remaining.
• On the SPI Transfer Complete Interrupt, store the received byte in the message abstraction structure but don't send the next byte until the timer fires again.
• When the full message has been sent, a further timer event is used to idle.
• ATTENTION goes high and a further set of timer events are used to stall before the next poll can take place. This is where the full message can be analysed.
The timer resolution is set to be equal to the length of the SPI transmission = (8 + extra) * the SPI clock in cycles. The extra causes delays between successive byte transfers, and also accounts for the time wasted responding to the timer interrupt.
The importance of doing this is in making sure the CPU is idle for as much time as possible. The way I'm modelling this in my head is to have the main thread of the CPU doing as little as possible, and all the interrupt sources performing the useful work. This way the main thread can run nothing but an endless loop of Doze state invokations, which means that whenever the CPU is serving an interrupt it'll process data at maximum speed, but when it's not it'll enter a low-power state where the necessary modules can still run at the correct speeds.
(* it's not multithreaded, but it's as good a way to consider this as any)
The vertical lines indicate timer events.
When a poll request occurs:
• ATTENTION is pulled low. Nothing else happens until the next timer event.
• Bytes are sent on successive timer events until none are remaining.
• On the SPI Transfer Complete Interrupt, store the received byte in the message abstraction structure but don't send the next byte until the timer fires again.
• When the full message has been sent, a further timer event is used to idle.
• ATTENTION goes high and a further set of timer events are used to stall before the next poll can take place. This is where the full message can be analysed.
The timer resolution is set to be equal to the length of the SPI transmission = (8 + extra) * the SPI clock in cycles. The extra causes delays between successive byte transfers, and also accounts for the time wasted responding to the timer interrupt.
The importance of doing this is in making sure the CPU is idle for as much time as possible. The way I'm modelling this in my head is to have the main thread of the CPU doing as little as possible, and all the interrupt sources performing the useful work. This way the main thread can run nothing but an endless loop of Doze state invokations, which means that whenever the CPU is serving an interrupt it'll process data at maximum speed, but when it's not it'll enter a low-power state where the necessary modules can still run at the correct speeds.
(* it's not multithreaded, but it's as good a way to consider this as any)
 Let's do it!
Let's do it!